Solving complex visual tasks such as "Who invented the musical instrument on
the right?" involves a composition of skills: understanding space, recognizing
instruments, and also retrieving prior knowledge. Recent work shows promise by
decomposing such tasks using a large language model (LLM) into an executable
program that invokes specialized vision models. However, generated programs are
error-prone: they omit necessary steps, include spurious ones, and are unable
to recover when the specialized models give incorrect outputs. Moreover, they
require loading multiple models, incurring high latency and computation costs.
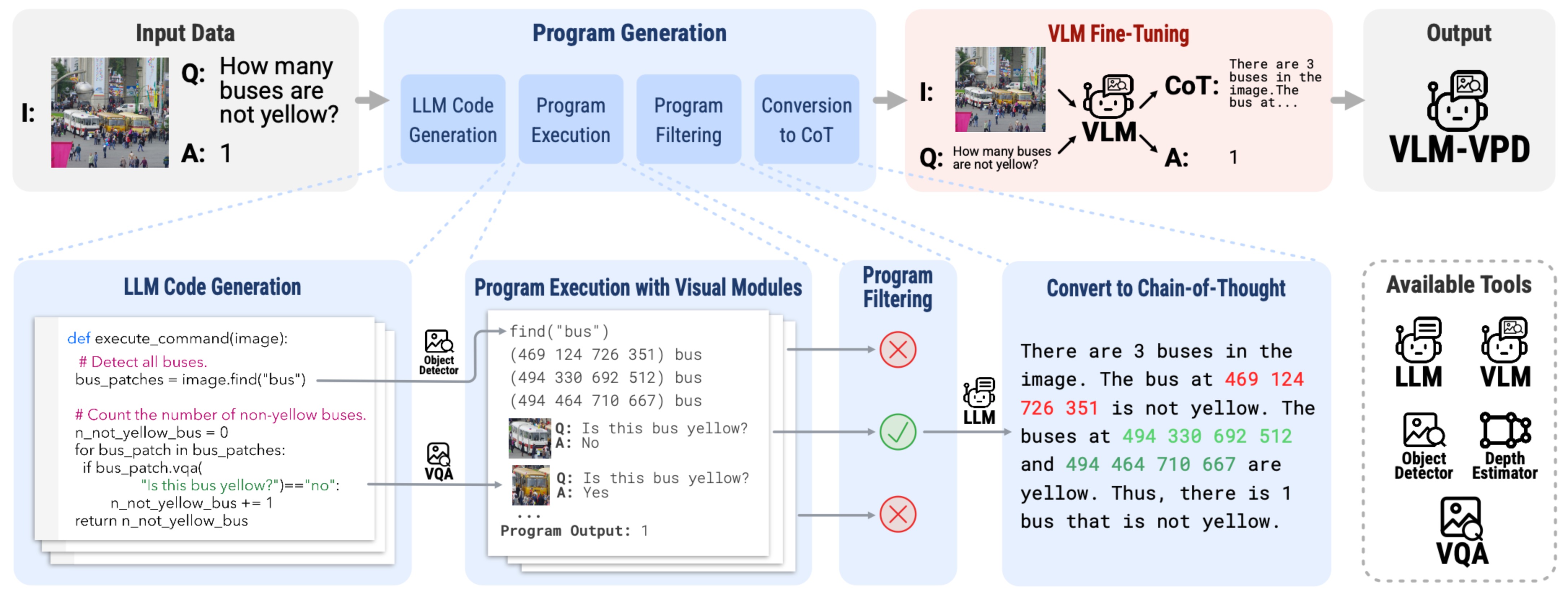
We propose Visual Program Distillation (VPD), an instruction tuning framework
that produces a vision-language model (VLM) capable of solving complex visual
tasks with a single forward pass. VPD distills the reasoning ability of LLMs by
using them to sample multiple candidate programs, which are then executed and
verified to identify a correct one. It translates each correct program into a
language description of the reasoning steps, which are then distilled into a
VLM.
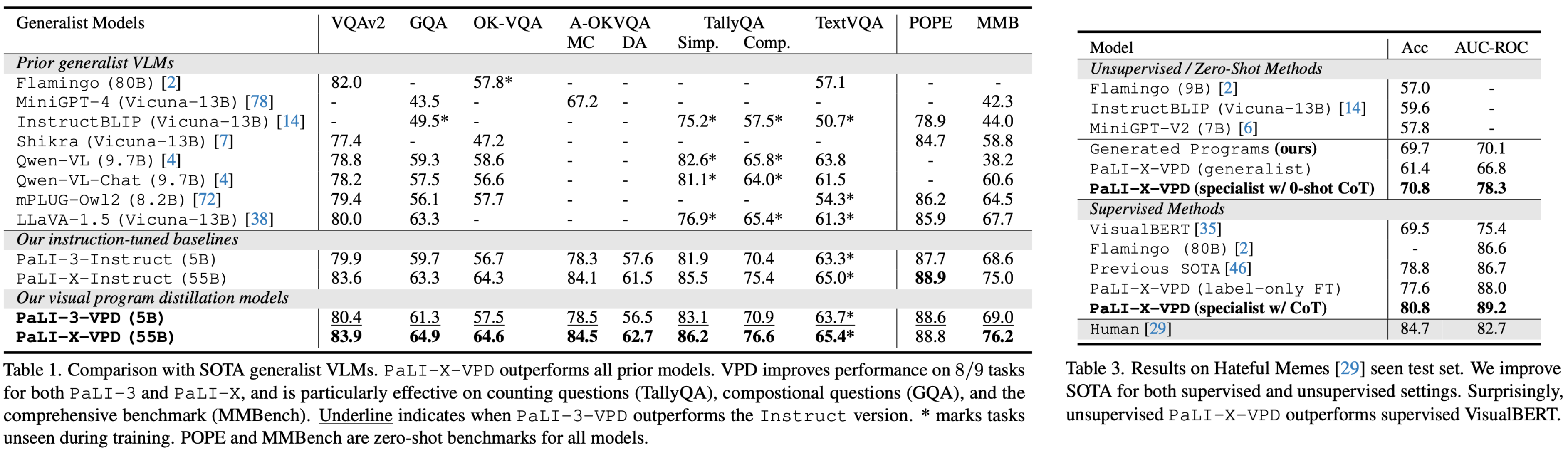
Extensive experiments show that VPD improves the VLM's ability to count,
understand spatial relations, and reason compositionally. Our VPD-trained
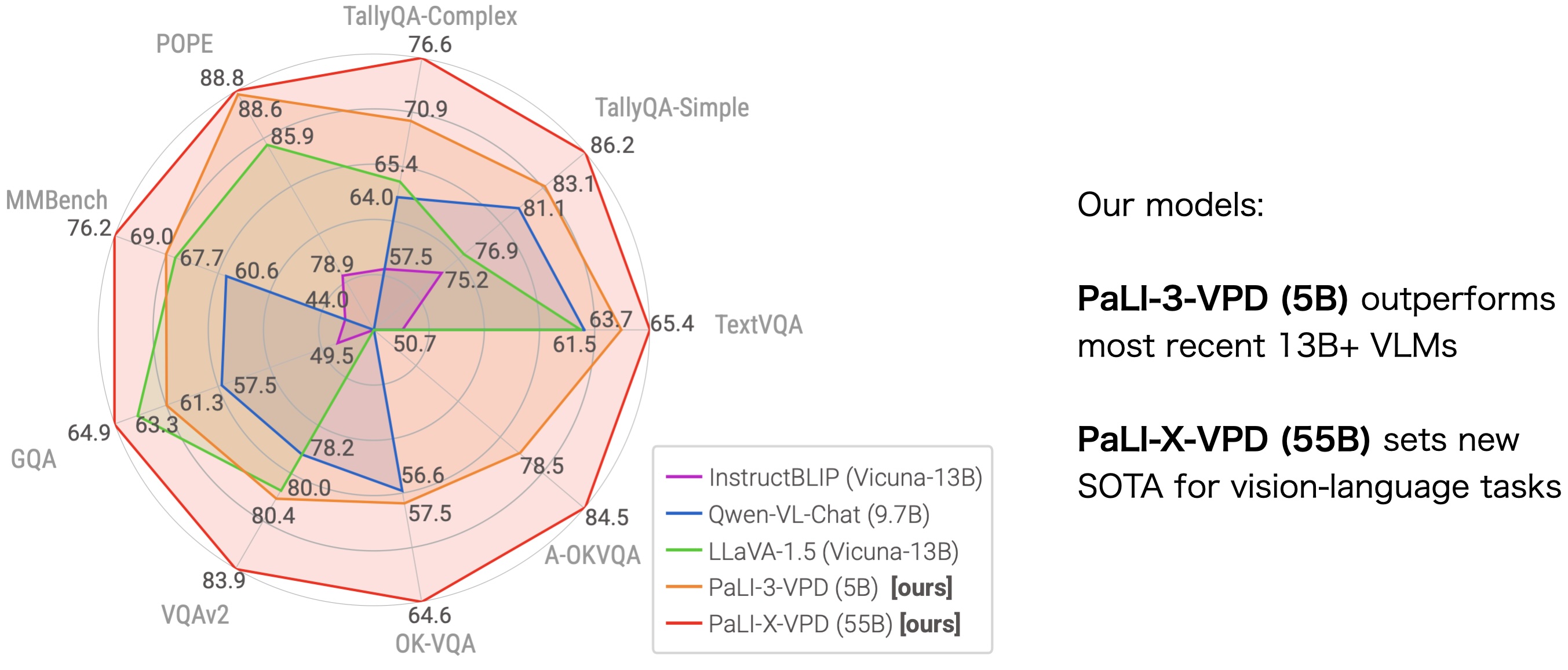
PaLI-X outperforms all prior VLMs, achieving state-of-the-art performance
across complex vision tasks, including MMBench, OK-VQA, A-OKVQA, TallyQA, POPE,
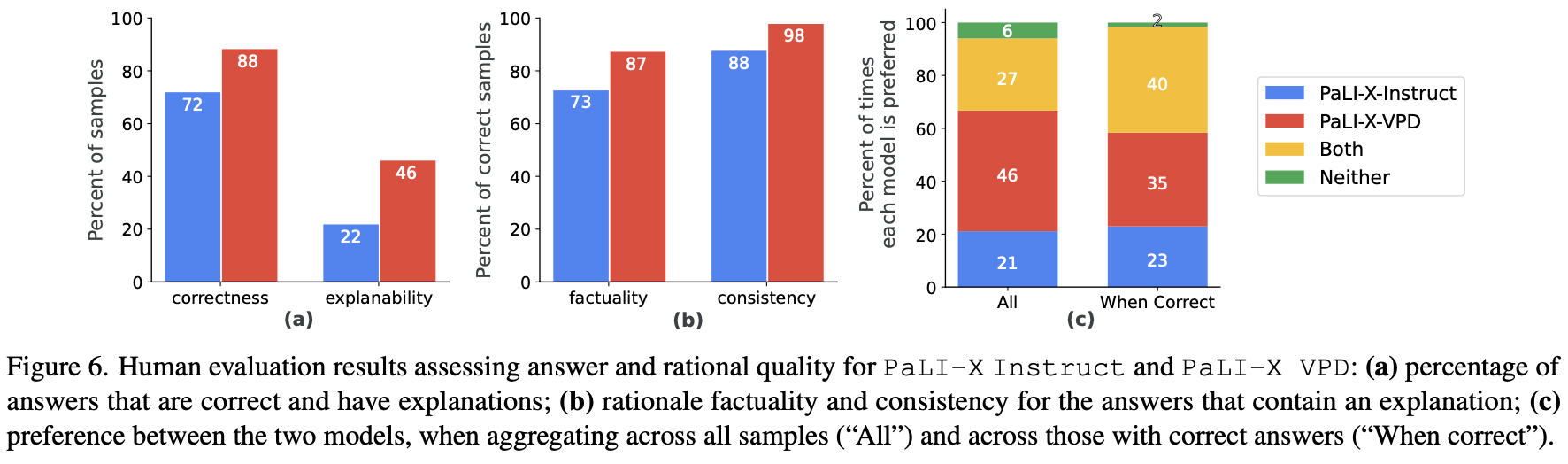
and Hateful Memes. An evaluation with human annotators also confirms that VPD
improves model response factuality and consistency. Finally, experiments on
content moderation demonstrate that VPD is also helpful for adaptation to
real-world applications with limited data.